What is theNeuReality
Solution?

The NR1™ AI Inference Solution is a holistic systems architecture, hardware technologies, and software platform that makes AI easy to install, use, and manage.
NeuReality accelerates the possibilities of AI by offering a revolutionary solution that lowers the overall complexity, cost, and power consumption.
While other companies also develop Deep Learning Accelerators (DLAs) for deployment, no other company connects the dots with a software platform purpose-built to help manage specific hardware infrastructure.
This system-level, AI-centric approach simplifies running AI inference at scale.
 NeuReality’s AI-Centric Approach
NeuReality’s AI-Centric Approach



Software/APIs
An ecosystem of upper-level AI tools for simplified deployment and orchestration

Architecture
Purpose-built and optimized for AI inference

Hardware
New network addressable system-on-a-chip to migrate simple but critical data-path functions from software to hardware

NeuReality Software
Develop, deploy, and manage AI inference
NeuReality is the only company that bridges the gap between the infrastructure where AI inference runs and the MLOps ecosystem.
We’ve created a suite of software tools that make it easy to develop, deploy, and manage AI inference.
Watch the video to learn more about our software.
Our software stack:

Works with any trained model in any development environment

Includes tools that offload the complete AI pipeline

Connects AI workflows easily to any environment
Any data scientist, software engineer, or DevOps engineer can run any model faster and easier with less headache, overhead, and cost.
NeuReality APIs
Our SDK includes three APIs that cover the complete life cycle of an AI inference deployment:
| Toolchain API | Provisioning API | Inference API |
| For developing inference solutions from any AI workflow (NLP, Computer Vision, Recommendation Engine) | For deploying and managing AI workflows | For running AI-as-a-service at scale |
NeuReality Architecture
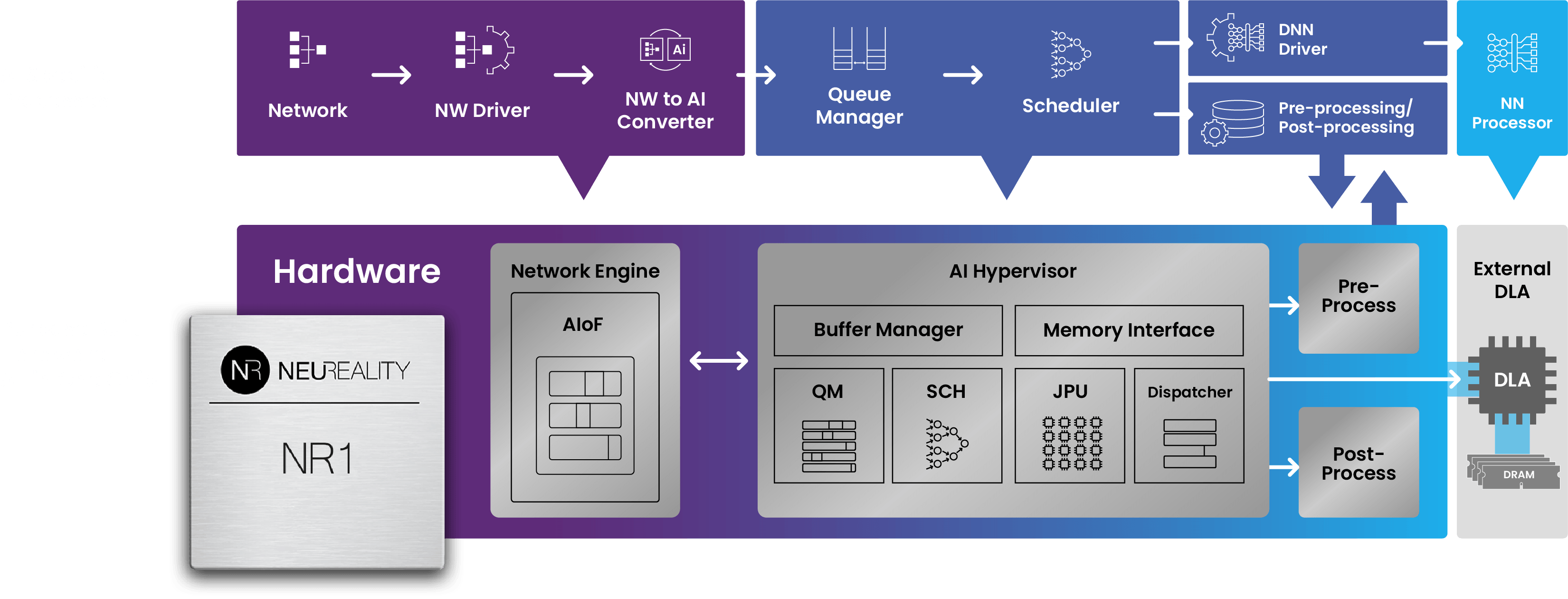
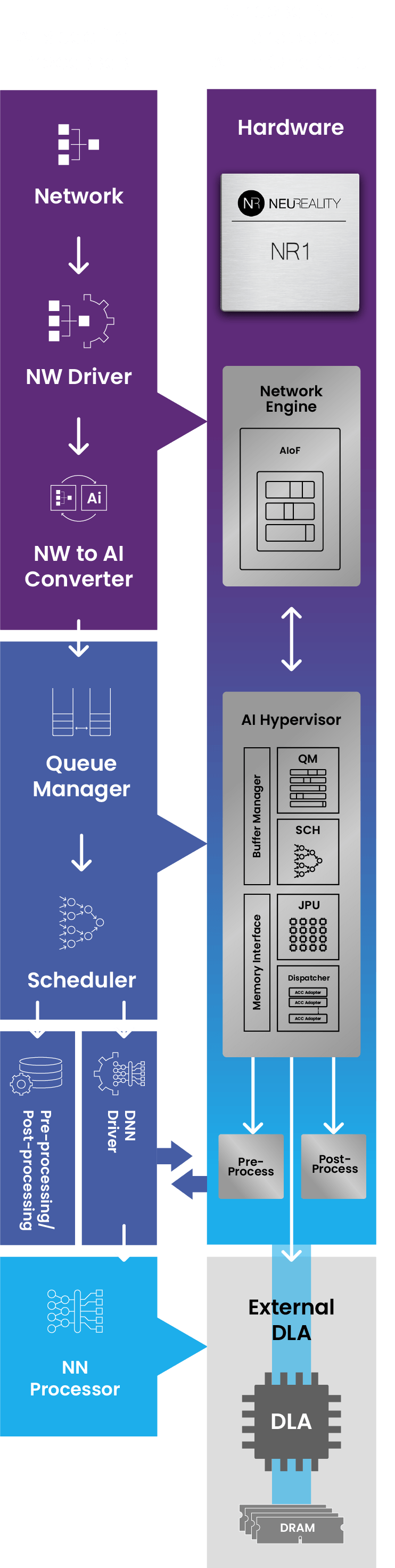
NeuReality has developed a new architecture design to exploit the power of DLAs.
We accomplish this through the world’s first Network Addressable Processing Unit, or NAPU.
This architecture enables inference through hardware with AI-over-Fabric, an AI-hypervisor, and AI-pipeline offload.
This illustration shows all of the functionality that is contained within the NAPU:
CPUs: Never Meant for Efficient AI Inference
Traditional, generic, multi-purpose CPUs perform all their tasks in software, increasing performance bottlenecks and delays (high latency). They were never designed for the computational or network demands of AI Inference at scale.
Our purpose-built NAPUs were designed specifically for the demands of high-volume, high-variety AI pipelines, performing those same tasks in hardware versus software. NAPUs are the ideal complement to AI Accelerator chips. They pair with any GPU, ASIC or FPGA taking them from low 30-40% utilization rates to 100% full potential. As a result, you can get more from the GPUs you buy, rather than buying more than you need – reducing silicon waste..
The following table compares these two approaches:
| AI Inference with NAPU | AI Inference with traditional CPU | |
| Architecture Approach | Purpose-built for Inference workflows | Generic, multi-purpose chip |
| AI Pipeline Processing | Linear | “Star” model |
| Instruction Processing | Hardware based | Software based |
| Management | AI Process natively managed by cloud orchestration tools | AI process not managed, only CPU managed |
| Pre/Post Processing | Performed in Hardware | Performed in software by CPU |
| System View | Single chip host | Partitioned (CPU, NIC, PCI switch) |
| Scalability | Linear scalability | Diminishing returns |
| Density | High | Low |
| Total Cost of Ownership | Low | High |
| Latency | Low | High, due to over partitioning and bottlenecking |
NeuReality Hardware


NR1 Network Addressable Processing Unit™
The NR1 Network Addressable Processing Unit (NAPU™) is the world’s first server-on-chip that connects directly to the network and comes with a built-in neural network engine.
NAPUs are designed to streamline AI workflows, featuring specialized processing units, integrated network functions, and virtualization capabilities. They excel in AI Inference tasks, providing optimal compute power for handling a wide range of AI queries and tasks, including text, video, and image processing for applications like Computer Vision, Conversational AI, and Generative AI.

NR1-M™ AI Inference Module
The NeuReality NR1-M™ module is a Full-Height Double-wide PCIe card containing one NR1 Network Addressable Processing Unit™ (NAPU) system-on-chip and a network addressable Inference server that can connect to any external AI Accelerator chip – XPU, FPGA, ASIC – to significantly optimize its utilization rate.

NR1-S™ AI Inference Appliance
NeuReality’s NR1-S™ is a groundbreaking AI server designed specifically for inference tasks – the deployment of many, diverse business AI applications. It uses NR1-M™ modules, each equipped with an NAPU, designed to pair with an AI Accelerator chip.
This setup ensures optimal performance and linear scalability, eliminating the usual CPU limitations. The NR1-S offers ideal, efficient AI system architecture, reducing costs and power consumption by up to 50% on average while maintaining top-notch performance.
