The 50% AI Inference Problem: How to Maximize Your GPU Utilization
In the 1800s, legendary retailer John Wanamaker famously said, “Half the money I spend on advertising is wasted; the trouble is I don’t know which half.”
Today, businesses and even some governments face a similar dilemma with their AI data centers, inference servers, and cloud computing investments. They spend millions on cutting-edge AI accelerators (GPUs, TPUs, LPUs….any “XPU”). But these expensive AI inference chips sit idle more than half the time, squandering resources and wasting expensive silicon.
The problem: ~50% GPU utilization
While headlines focus on the high cost and energy consumption of AI inferencing – the daily operation of trained AI models – a less visible crisis lurks within data centers: GPU underutilization. Gartner analyst Samuel Wang warns that “the scalability of generative AI is constrained by semiconductor technology.” (Emerging Tech: Semiconductor Technology Limits GenAI Scaling, December 26, 2023). He urges data center leaders to prioritize efficient software and more modern chip architectures to optimize AI infrastructure now – to prepare for today’s and tomorrow’s demand AI inference performance needs without breaking the bank.
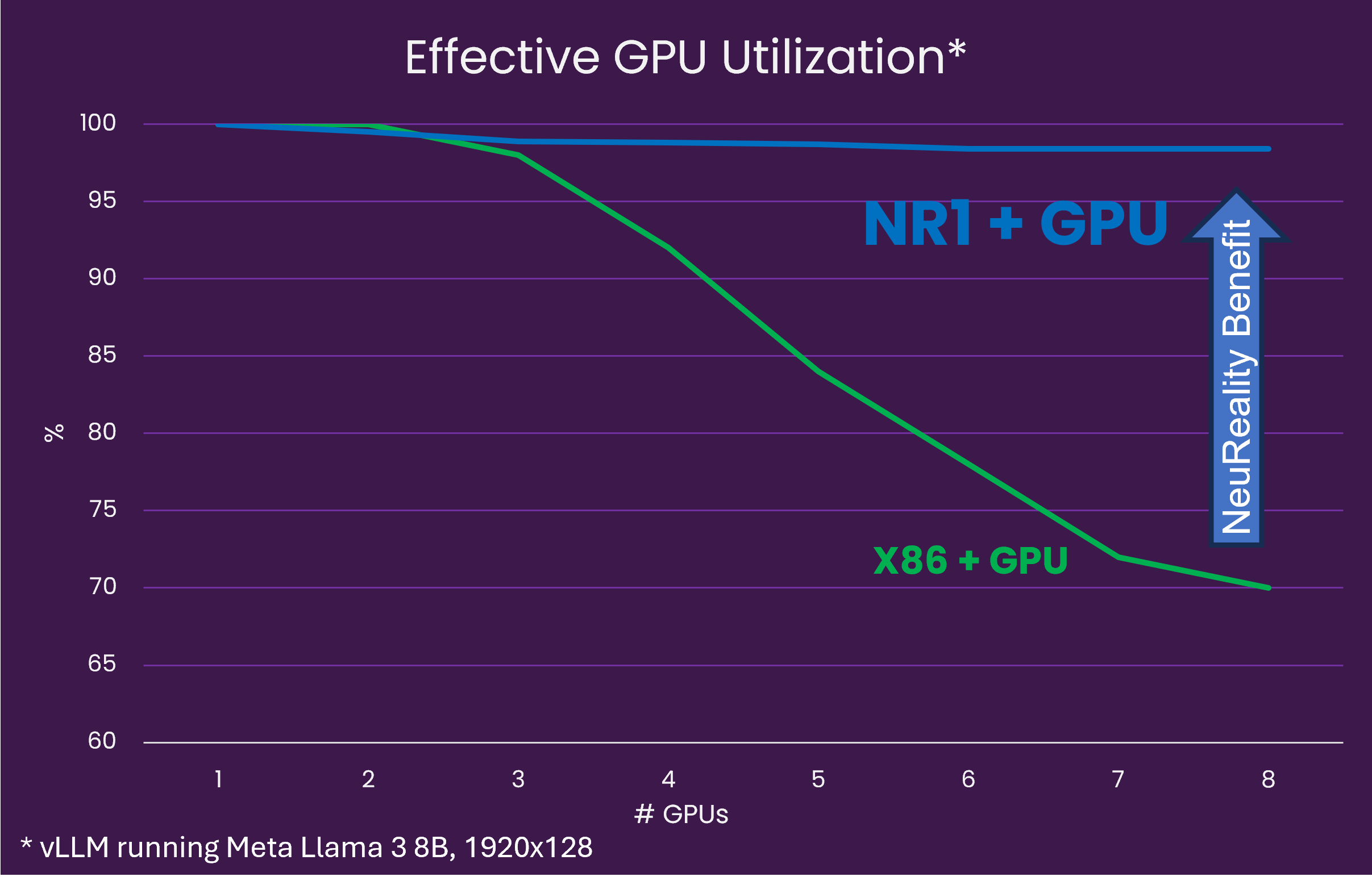
Here’s one of the root causes: Most AI accelerators, including top chips from NVIDIA and AMD, run under 50% capacity in AI inference, causing significant waste and unnecessary power use. The main issue lies not with the AI accelerators but with the outdated, decades-old x86 host CPU system architecture. After all, it was never designed for complex, high-volume AI queries from generative, agentic, or conversational AI.
Remember, data center CPU limitations led to AI accelerator innovation in the first place. But now AI applications, software, APIs, and hardware accelerators outrace the rate of innovation in the underlying system architecture; that is, until NeuReality.
the solution: next-wave AI iNFERENCE ARCHITECTURE
Our purpose-built AI Inference system architecture, powered by a unique 7nm NR1 server-on-chip, changes that. When paired with any AI accelerator, the NR1 super boosts GPU utilization from under 50% today to nearly 100% maximum performance with NR1 architecture. Now, you can access that ultra-efficient technology in a single, easy-to-use, AI Inference Appliance. It comes pre-loaded with fully optimized enterprise AI models including Llama 3, Mixtral, and DeepSeek running at a lower cost per token per watt.
These exciting efficiency breakthroughs are encouraging NeuReality’s tech partners and customers to rethink their AI setups in a big way, aiming to streamline their systems and boost efficiency by moving away from traditional CPU architecture.
As you saw in the DeepSeek R1 distilled releases last month, and NeuReality’s subsequent test, efficiency is the name of the AI game in 2025 and beyond in open-source software and hardware alike:
Key strategies to boost GPU utilization include:
- Minimizing data movement: Keeping data close to compute engines to reduce latency;
- Specialized compute engines: Incorporating specialized processors for tasks like pre- and post-processing to ensure balanced performance;
- Streamlined data paths: Eliminating unnecessary data transfers through the host CPU and NIC to improve efficiency. NeuReality’s NR1 chip subsumes both the CPU and NIC functions – and drives an order of magnitude improved performance.
The Industry Responds
The issue of underutilized AI accelerators is now gaining significant attention within the industry. Leading companies such as NVIDIA, AMD, and cloud service providers are investigating innovative methods to enhance efficiency and reduce cost barriers to enterprise adoption. Cirrascale, for example, is actively selling NeuReality’s AI Inference Appliance loaded with NR1 AI Inference cards paired with Qualcomm Cloud AI 100 Ultra accelerators – no CPUs required.
These initiatives underscore a growing awareness: the future of AI adoption depends on computational efficiency. As AI becomes integral to business operations, the emphasis shifts from sheer computing power to achieving radical efficiency. Enhancing GPU efficiency necessitates fundamental changes, and several strategies have been developed.
- Memory Optimization: Bringing memory closer to the GPU, often through High Bandwidth Memory (HBM), addresses memory bandwidth challenges.
- On-Die SRAM: While power-efficient, the limited capacity of SRAM necessitates large-scale clusters to accommodate even small models.
- GPU Cluster Scale Up: Scaling up clusters allows for efficient processing of large models using devices with limited individual capacity.
However, these approaches primarily focus on the model and GPU scaling.
AI inference differs from AI training because it targets specific business applications and requirements. The model functions as a component within a larger application. Optimizing the overall system, not just the Accelerator or GPU, is critical.
Disruptive technology in one simple server appliance
Recognizing the limitations of focusing solely on the Accelerator, we’ve optimized the overall AI inference system through architectural innovation, a 7nm server-on-chip that displaces the traditional host CPU, plus critical software integration. Today, we deliver maximized Accelerator utilization in an easy-to-use, software-equipped, and quick-to-install AI Inference Appliance. How easy? The first installation at Cirrascale – our first cloud computing partner – had the appliance up and running in 30 minutes.
Our enterprise-ready solution also empowers customers to deliver Generative AI customer experiences 3x faster due to the advantages of NeuReality Software and APIs – for example, in this Llama 3 call center application at Supercomputing 2024. The market-disrupting approach of replacing the host CPU and NIC with advanced NR1 system architecture yielded stunning results. For Large Language Model applications such as Llama 3, Mistral, and RoBERTa, we deliver:
- Near 100% GPU effective utilization – versus <50% with outdated CPU-centric architecture
- 50-90% price/performance gains – with the lowest cost per token
- Up to 15x greater energy efficiency – with the lowest AI cost per watt
Technology analyst Matthew Kimball from Moor Insights & Strategy summed up his visit to NeuReality’s Appliance demonstrations at SC24:
“Silicon innovation is on another level. I don’t think I’ve ever seen so much innovation at the chip level. Call me crazy, but if you think NVIDIA’s next big threat is AMD, Intel, Qualcomm, or Arm – you may be right. Or it may be a small company that has the freedom to think and address compute challenges differently.”
– Matthew Kimball, AI Analyst, Moor Insights & Strategy

See It to Believe It
Let us demonstrate or share competitive comparisons of AI application workloads and hardware accelerators running on NR1 versus CPU-centric architecture. Here’s how:
- If you are a financial services, healthcare, biotech, or government organization: Test drive the complete silicon-to-software NR1-S AI Inference Appliance to see the difference. It’s easy to use and fast to install with the lowest Total Cost of Ownership. For an on-premise or cloud proof-of-concept, contact us at hello@neureality.ai.
- If you are an AI chip, hyperscaler or cloud service technology company: Partner with us to build a customer Appliance or use our NR1-M AI Inference Module (PCIe card) paired with your preferred AI accelerator or GPU. For Partner Program opportunities, contact sales@neureality.ai.