
June 2024 Competitive Performance Results
Knocking Down AI Inference Cost and Energy Barriers
I. Introduction
by NeuReality CTO, Lior Khermosh and Chief R&D Officer, Ilan Avital
This is an important day for NeuReality. We are proud to share our first real-world performance results running multiple, full-scale AI pipelines on the NR1-S™ AI Inference Appliance coupled with leading AI accelerators from Qualcomm® Technologies Inc.* These performance findings show that AI inference can be run at a much lower cost – in capital expenditure, operating expenses, and energy consumption – than the CPU-reliant AI Inference systems being forwarded by the industry today.
Today’s AI infrastructure relies on CPU-centric system architecture hosting AI accelerators like NVIDIA** GPUs. This setup significantly limits the potential of AI accelerator systems, as their CPU hosts are a serious performance bottleneck in AI inference servers leading to inefficiencies in cost, energy consumption, and space utilization.
Four years ago, NeuReality system engineers, technologists, and software developers came together to change the underlying infrastructure of AI Inference servers – bridging the gap between the development of advanced ML/AI models and their deployment to become far more efficient and affordable.
Today, about 35% of global businesses and only 25% in the U.S. have adopted AI***, due in large part to the prohibitive expense of operating AI data centers. Left unaddressed, these barriers will persist according to Predictions by Gartner® stating, “AI Data Center Power Usage, 2022-2027.”****
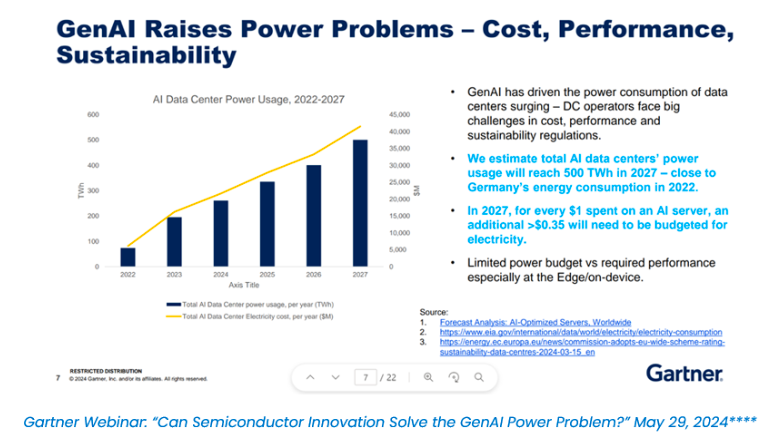
NeuReality’s AI architecture offers a far more sustainable path forward, enabling enterprises, government agencies, and educational institutions to utilize AI to its full potential while decreasing cost and energy consumption in AI data centers.
Generative AI has sent power consumption in data centers surging – a crisis in cost and limited energy supply. These are problems that NeuReality foresaw at its founding in 2019 and has worked to solve, now with a commercially available NR1-S AI Inference Appliance with impressive performance results.
Our quantitative findings underscore the necessity for the AI industry to make a conscientious effort to shift away from CPU-centric architectures toward NR1 system architecture. By doing so, customers can achieve significant improvements in performance, cost-efficiency, and energy consumption, ensuring AI technologies are accessible to all. As AI pipelines grow exponentially in query volume, variety, and multimodality now and in the years to come, putting extra pressure on AI data centers, it is important now to fortify both on-premises and cloud data centers with a modern “made-for-AI inference” NR1 system architecture.
II. Performance insights
In May 2024, real-world performance tests were conducted by NeuReality for the first time “on silicon”; that is, on actual hardware in a data center-like environment. These tests utilized commercially available equipment, comparing the NR1-S with both Qualcomm® Cloud AI 100 Pro* and Cloud AI 100 Ultra* against CPU-centric systems with NVIDIA® L40S** and H100**.
In all testing, we compared various AI pipelines across model and full AI workloads – creating real-world scenarios for diverse modalities including text, audio, and images – specifically for Conversational AI and Computer Vision. We measured key AI inference KPIs using Cost per AI Query (sequences, frames, audio seconds) relative to CPU-centric servers based on premium-priced Nvidia H100 and mid-market Nvidia L40S used in both AI training and inferencing. In every use case, NR1-S combined with AI 100 Ultra significantly reduced cost versus the CPU-centric H100 and L40S systems – with an average of 90% savings as seen below.
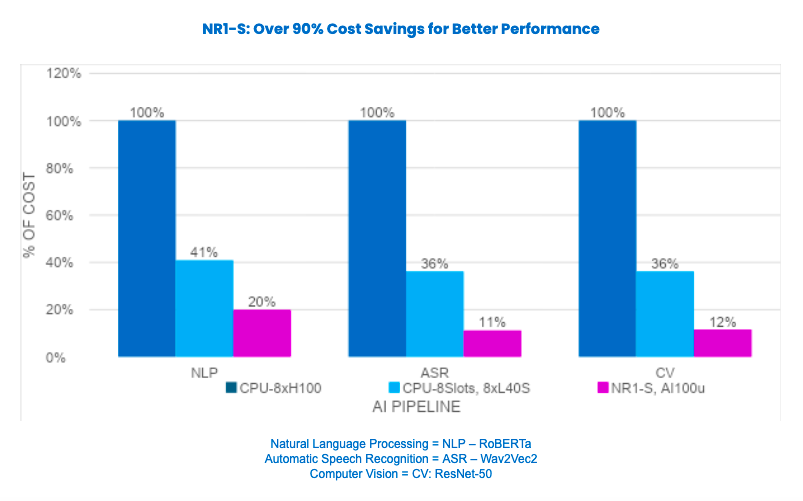
Conversational AI Examples
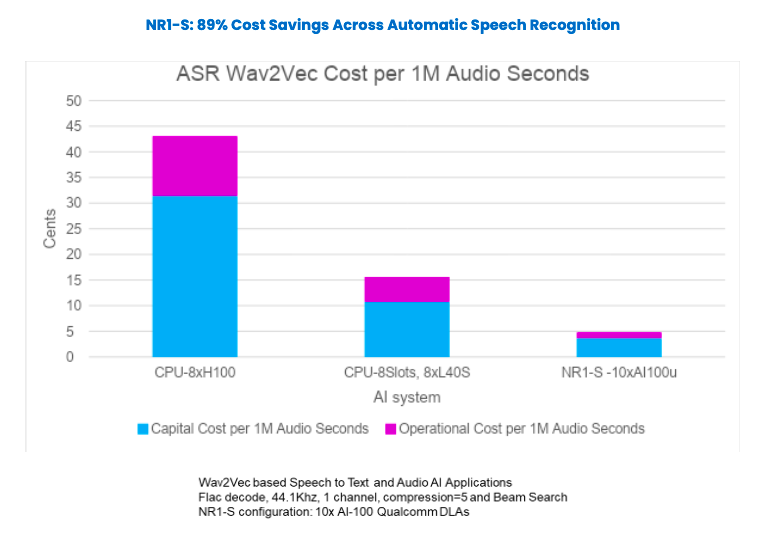
Let’s zoom in on the ASR example, now showing the breakout of capital and operational cost per 1 million audio seconds, and the significant 88% cost savings by moving from CPU-centric to NeuReality system architecture.
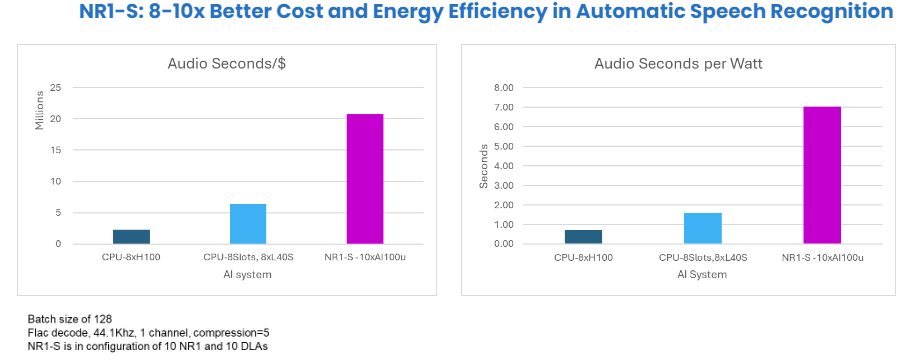
The second set of performance tests focused on energy and cost efficiency. For all the AI pipelines tested, we adopted AI Query per Second Per Dollar including a measurement of energy consumption (Watt Hour). Side-by-side comparisons show the combination of cost and energy efficiency for both the cost of capital and operational expenses for a total ROI view.
For the ASR example, we utilized the Wav2Vec2 base model for voice-to-text transcription, configured with a Beam search of 128. The audio input was decoded from FLAC format at 44.1kHz with one channel and a compression level of 5. The NR1-S appliance was configured with 10 NR1-M units and 10 AI-100 Ultra units. The results demonstrated a 3.2x advantage in performance per dollar for the NR1-S configuration compared to an NVIDIA L40S CPU-centric server, and an overall 8-10x increase in better cost and energy efficiency.
Take another example from Natural Language Processing (NLP). We employed a RoBERTa-based model for chatbot intent detection, configured with sequences of 128 tokens. The NR1-S system was set up with 16 AI 100 Ultra accelerators. Compared to the NVIDIA L40S CPU-centric system, this NR1-S/AI accelerator configuration outshines CPU-centric again with an overall 5-6x improvement in cost and energy efficiency.
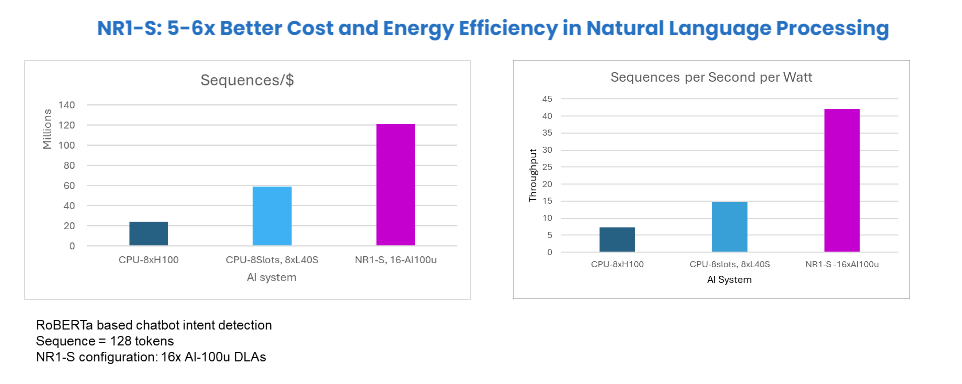
Computer Vision Examples
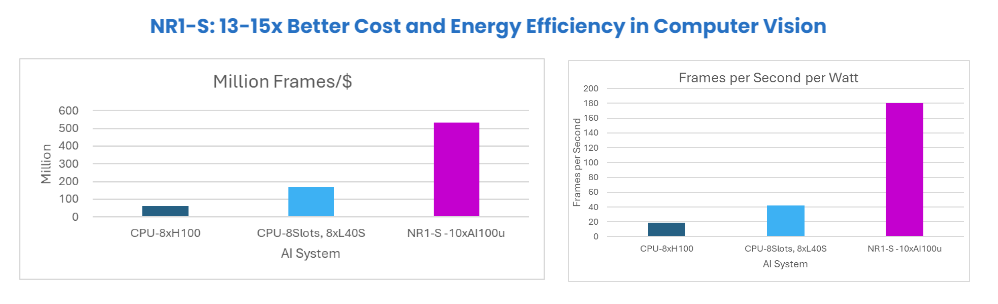
Zooming in on object classification, you see the most dramatic improvements across price/per performance, cost and energy efficiency, and linear scalability; meaning, zero performance drop-offs as more AI 100 Ultra units are added to manage growing business AI workloads.
Recall earlier that with NR1-S and AI 100 Pro versus CPU-centric Nvidia systems, we saw a 90% cost savings improvement using ResNet50. As seen below, NR1-S with AI 100 Ultra also delivers the most noteworthy Computer Vision results with 13-15x better cost and energy efficiency.
Our final performance and scalability tests demonstrate that NeuReality also boosts performance efficiency through perfect linear scalability and full AI accelerator utilization when integrated with NR1-S.
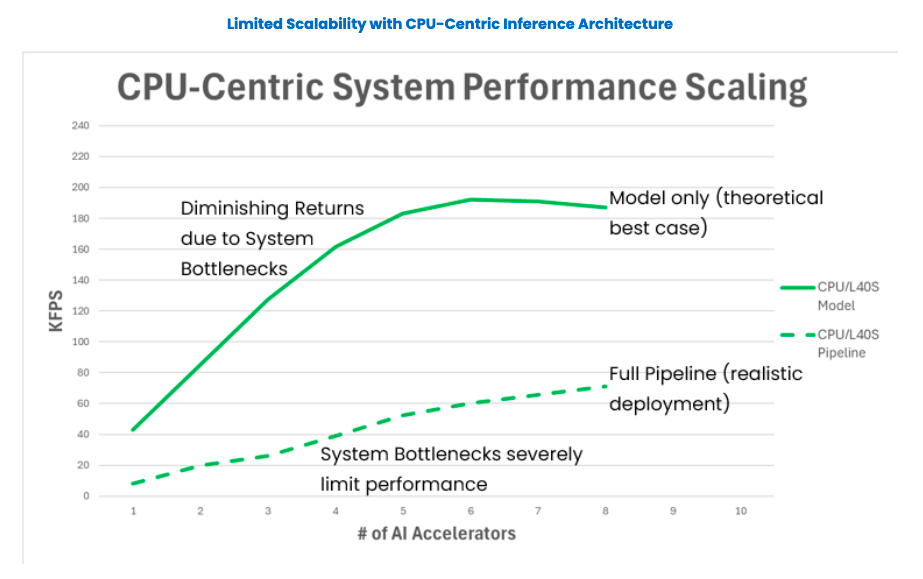
We began our tests with computer vision using ResNet-50 – a 50-layer deep convolutional neural network known for its high accuracy and robustness in image recognition. The testing included the model alone and the full AI pipeline, including JPEG decoding.
The following graph illustrates CPU performance bottlenecks with the NVIDIA L40S. A single L40S reaches 40 KFPS, but 8 GPUs are limited to 190 KFPS for the model only (instead of 320 KFPS) due to system data movement and processing constraints. Performance further degrades with pipeline processing. As AI workloads grow and more GPUs are added, system performance continues to degrade.
In contrast, pairing NR1-S appliances with Qualcomm Cloud AI 100 Pro units maximizes these powerful AI accelerators, ensuring they reach their full capability, higher density, and true linear scalability, unlike CPU-reliant Nvidia L40S systems. The NR1 architecture achieves that by implementing a novel AI-over-Fabric™ network engine, a hardware-based AI Hypervisor™, and a unique mix of heterogeneous compute engines, all aimed to streamline the required AI pre- and post-processing and efficient movement of data. This is explained further in the next Section IV below.
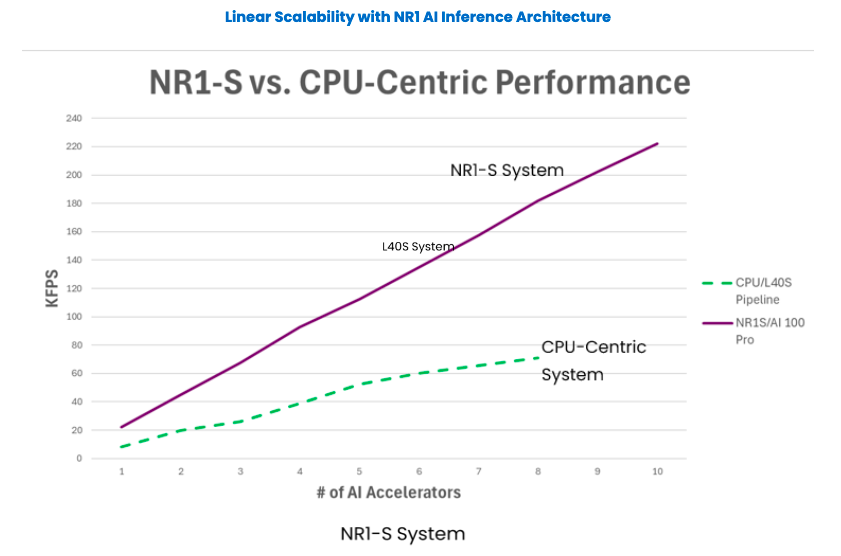
Overall, NeuReality achieves 100% AI accelerator utilization up from an average of 30-40% today without performance drop-offs or delays as new units are added. This combination of efficiency, affordability, and sustainability reduces costly energy consumption at the source – the AI data center itself.
III. High-Level Understanding of NR1 System Architecture
At its inception, NeuReality reimagined a new AI Inference system architecture. After breaking down and analyzing each critical business and technical requirement for large-scale AI deployment, it became clearer where and how AI inferencing infrastructure differs from AI training infrastructure and what needs to change in the AI age. NeuReality put forth a complete silicon-to-software AI Inference solution that displaces the CPU to achieve key business and performance needs in inference. The team designed and developed it from the ground up culminating with TSMC manufacturing the world’s first 7nm NR1 NAPU (Network Addressable Processing Unit).
CPU-Centric System Architecture: Today’s AI accelerators are hosted by CPUs with Network Interface Controllers (NICs) to manage data between AI clients, servers, and storage. This complex integration limits performance and scalability as AI demands grow.
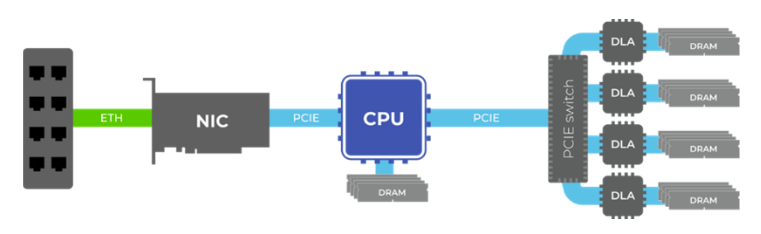
NeuReality AI System Architecture: In contrast, NR1-S overcomes CPU performance bottlenecks and drop-offs as AI deployments scale with growing and more complex workloads. By offloading data movement and processing to the novel 7nm NR1 NAPU shown below, NeuReality makes perfect linear scalability and full AI accelerator utilization possible. This is just as important with today’s conversational AI, recommendation engines, and computer vision as with future multimodality and generative AI workloads whether large or small language models.
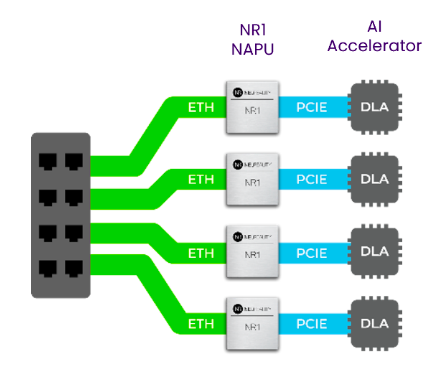
The NeuReality architecture forms a heterogeneous compute cluster that offloads the entire AI pipeline:
- – Integrates management, sequencing, quality of service, control functions, and connectivity, resulting in superior performance, cost efficiency, energy savings, and space efficiency.
- – Interfaces seamlessly with any AI accelerator system with GPU, FPGAs, or ASIC. The NR1™ AI Inference Solution is a complete silicon-to-software system that includes everything needed to deploy and manage business AI applications.
- – Includes user-friendly software tools and interfaces that make it easy to set up and run AI projects. The NR1 manages everything from coordinating resources to processing queries from remote users.
Our software stack simplifies the process of deploying AI solutions for developers to optimize and manage AI tasks. This system allows businesses to access AI services efficiently over standard network connections, ensuring high performance with minimal delays. For more information on the value of our Software, APIs, and Software Development Kit, watch this short software video.
In this blog, we focused on full pipeline performance results from NR1-S appliances running with AI 100 Pro and Ultra. Together, they eliminate CPU bottlenecks and liberate AI data centers from high cost and energy consumption.
To go inside our end-to-end NR1 AI system architecture and NR1 NAPU microarchitecture with in-depth diagrams and details, request a copy of our Technical Whitepaper by contacting us at hello@neureality.ai.
IV. Testing Methodology
NeuReality’s testing methods spanned a comprehensive evaluation of full pipeline AI capabilities, focused first on a Computer Vision pipeline for image classification utilizing the ResNet-50 AI model. Further extrapolations and measurements were made for Natural Language Processing (RoBERTa), and Automatic Speech Recognition (Wav2Vec2) pipelines.
Competitive comparisons focused on the performance per dollar and performance per watt of the NR1-S versus a CPU-centric inference server loaded with AI accelerators.
The initial tests included a full system setup for disaggregated AI inference service over a network managed in a Kubernetes cluster. The testbed subjected the AI inference server to stress load by sending ResNet-50 INT8 inference requests from multiple clients over the network, returning the results to the clients after inference on the AI server. The tests measured Frames per Second (FPS) per dollar and FPS per watt, comparing the NR1-S with the CPU-centric inference server. The testing architecture is illustrated here:
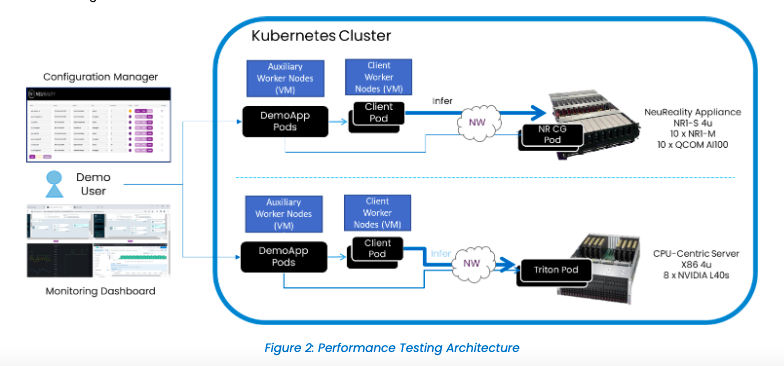
Stress Testing and Real-World Scenario Simulation:
Stress testing involved sending ResNet-50 INT8 Inference requests from multiple clients over the network. This rigorous approach provides valuable insights into the operational efficiency and cost-effectiveness of AI systems under real-world AI workload conditions for cloud and enterprise data center deployments.
For image classification, the test workload is described here:
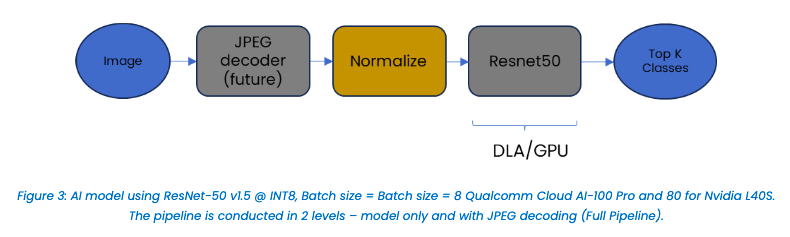
AI Pipeline Evaluation:
– Model-only Pipeline: ResNet-50 (normalized data served from client)
– Full Pipeline: Decode → Resize → Crop → Normalize → ResNet-50 (JPEG images served from client)
– ResNet-50 running on AI 100 Pro or NVIDIA L40S
– Pre-processing running on NR1-S versus CPUs/GPUs
Hardware Setup:
– Two client machines, each with NVIDIA CNX5 (dual 100G port) with MTU 9000
– One server machine with 8 AI 100 Pro and 2 NVIDIA CNX6 (dual 100G ports each) with MTU 9000
– Nvidia Triton servers running on CPUs in NUMA with NUMA affinity, and NIC traffic on the same NUMA.
– 10 clients per server with 100 outstanding requests per client
Performance Metrics:
– Frames per Second (FPS)
– FPS/dollar and FPS/watt
– Watts (W) consumption
– Comparison between NR1-S with AI 100 Ultra and Pro versus NVIDIA H100 and L40S with CPU hosts in all test cases and data types
V. Real-World Implications
Early business AI adopters, analysts, and press have reported on big AI challenges in 2023-2024; namely, the high cost, high power consumption, and performance lags when trained AI models are deployed in both cloud and enterprise data servers – what we call an undesirable “brute force” solution. The OpenAI phenomenon certainly brought the lack of sustainability to the fore.
Some of the earliest warnings came from Sam Altman, CEO of OpenAI, a few months into the launch of ChatGPT and its later upgrades. Recently, Bloomberg laid out the current, costly momentum of AI accelerator companies perfectly in “Why Artificial Intelligence is So Expensive.”
It serves as a reminder that raw speed and performance in individual components alone – the AI accelerators (GPUs, FPGAs, ASIC) will not solve the problems in AI inference. Instead, we encourage you to test and compare CPU-centric vs NeuReality architecture, much like how well-planned transportation systems and sensors are crucial to carry the fastest race cars, sports sedans, SUVs, and large, slow trucks.
While the authors did not outrightly cite CPU-reliant AI inference servers as the root cause, the CPU undoubtedly plays a very large part as an inherent mismatch to the needs of today’s on-premises and cloud service data centers – predicted four years ago at the inception of NeuReality. However, rather than seek an efficient systems-level solution, the industry inertia to fund and build more and faster AI chips which by itself will solve nothing.
Our competitive performance results serve as a reminder that improvements in individual components alone cannot solve the larger system inefficiencies in AI deployments. That is why we were anxious to share today’s results with the AI industry – and to our mutual understanding of the opportunities ahead with this promising news for all.
While Nvidia, large hyperscalers, and others downplay CPU usage and reliance on their AI inference systems, the fact is that CPUs remain their biggest single choke point. Current data center infrastructure relies on CPUs for tasks like setup, preprocessing, coordination, and control logic, and yet, ironically, they stifle the full potential of those very AI accelerators in the AI servers themselves.
NR1-S is agnostic, open source, and a complementary system to any GPU or any AI accelerator in AI inference servers. We aim to displace the outdated, invisible system architecture. Therefore, we encourage you to test and compare CPU-centric vs NeuReality architecture, much like how well-planned transportation systems and sensors are crucial to carry the fastest race cars, sports sedans, SUVs, and large, slow trucks.
VI. Future Prospects
The numbers released today speak to significant performance gains, energy efficiency, and cost savings with NR1 versus CPU-centric system architecture. They also underscore that problems will only worsen as heavier AI workloads and subsequent AI accelerators are added for Generative AI and other complex pipelines.
Faster GPUs alone do not solve a system problem; in fact, they only make it worse.
Generative AI and Multimodality
The foundational text, image, and sound pipelines that we measured in Computer Vision and Conversational AI represent core building blocks for the new and evolving Generative AI pipelines including large language models (LLMs), Mixture of Experts (MOE), Retrieval Augmented Generation (RAG) and Multimodality.
Let’s take an example. The RAG vector search pipeline is a key component that allows users to customize their LLM with their own databases. It injects information into the LLM context and relies on a similar NLP pipeline with an even more complex similarity vector search which further burdens the system.
Of course, LLMs are not limited to text only. They can include multimodality (multiple data types in the same trained model) to support images, video, audio, and more. So, like the singular modalities we share here, multimodal pipelines also require a far more efficient AI inference systems infrastructure to handle significantly larger media and data movements simultaneously, pre- and post-processing compute for AI media types and additional front-end networks. CPU-centric architecture does not offer these capabilities, but NR1-S does.
Put another way, whatever cost and energy challenges that traditional AI pipelines suffer from now only worsen with more complex LLM and multimodal pipelines. Throwing more and faster GPUs at a systems problem only makes it worse because overall price/performance, cost, and energy efficiency decrease further.
Future Performance Testing
In the future, we will release generative AI performance results across different pipelines and configurations, as well as results from ongoing proofs of concept (POC) in customer production environments. NeuReality is also testing complex workloads such as LLM, MOE, and RAG and we plan to share those results later in 2024 once completed. We expect comparable results as they also run on CPU-centric architecture and face the same performance constraints.
Further, NR1-S is an agnostic, general-purpose solution designed exclusively for AI inferencing, to improve the output of any AI accelerator and to manage the high volume, variety, and velocity of current and future AI applications both singular and multimodality.
VII. Summary
NeuReality’s fully integrated NR1 AI Inference Solution addresses the triad of obstacles hindering widespread enterprise AI adoption today: excessive energy consumption, exorbitant costs, and high complexity.
Currently, every major player in the AI semiconductor market – from NVIDIA and Google to AMD and Intel – relies on CPU-centric architecture to build their AI inference servers. That reliance is the single biggest cause of our current AI cost and energy crisis for running large-scale trained AI applications. The problem only worsens with the current inertia of faster and faster AI accelerators that degrade overall AI system performance.
NeuReality delivers affordable AI through:
– Hardware Unit Reduction: Decreasing the number of AI accelerators needed by optimizing each one with NR1-S, enhancing production viability.
– Hardware Price Reduction: Offering cost-effective NR1-S hardware without compromising performance or scalability.
– Cost & Power Optimization: Improving service availability with a better cost/power structure, with a smaller carbon footprint in both real estate space and daily energy consumption.
Click here for more detailed NR1-S specifications, features, and benefits.
Our inaugural real-world performance tests validate our approach, paving the way for ongoing testing on generative AI and more to solve the energy and cost crisis growing in the world’s AI data centers. Stayed tuned for the next report.
VIII. a Call to Action
We look forward to working with Qualcomm for further testing on LLMs and multimodal pipelines with NR1-S in the weeks ahead. We also invite cloud service providers, hyperscalers, AI software, and hardware innovators to test, compare, and optimize their solutions on NR1-S versus CPU-centric infrastructure.
The primary challenge is reshaping an entrenched CPU-centric paradigm in our industry. We call upon our fellow technologists and engineers to embrace a transformative AI inference solution that removes market barriers for business and government customers while getting more from the AI accelerators they buy.
Simply put, NeuReality’s innovation signals an evolution from CPU-centric to a new reality in AI inference.
Contact us at hello@neureality.ai for a deeper conversation.
© 2024 NeuReality. All rights reserved.
NR1 AI Inference Solution, NR1-S and NR1 NAPU are trademarks of NeuReality.
ResNet-50, Wav2Vec, and RoBERTa are names or trademarks of their respective owners. All other trademarks mentioned herein are the property of their respective owners. Use of third-party trademarks does not imply endorsement or affiliation.
*Qualcomm and the Qualcomm logo, Cloud AI 100 Pro, and Cloud AI 100 Ultra are trademarks of Qualcomm Incorporated, registered in the United States and other countries.
**NVIDIA,NVIDIAL40S GPU, and NVIDIA DGX H100 are trademarks of NVIDIA Corporation.
***Exploding Topics, How Many Companies Use AI, May 2024
****Gartner, Webinar: Can Semiconductor Innovation Solve the GenAI Power Problem? 29 May 2024.
GARTNER is a registered trademark and service mark of Gartner, Inc., and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.